Most organizations have crucial knowledge scattered across a large number of documents, such as, technical manuals, knowledge articles, patents, policy documents, contracts and scientific publications, often in varied formats. Huge value is created by making this knowledge searchable and extracting the valuable insights therein. To this end, Inscripta’s ParseQa suite of libraries builds on the latest research in Document Processing, NLP and Search to create cutting-edge solutions that can be customized for a variety of domains and use-cases with little effort.
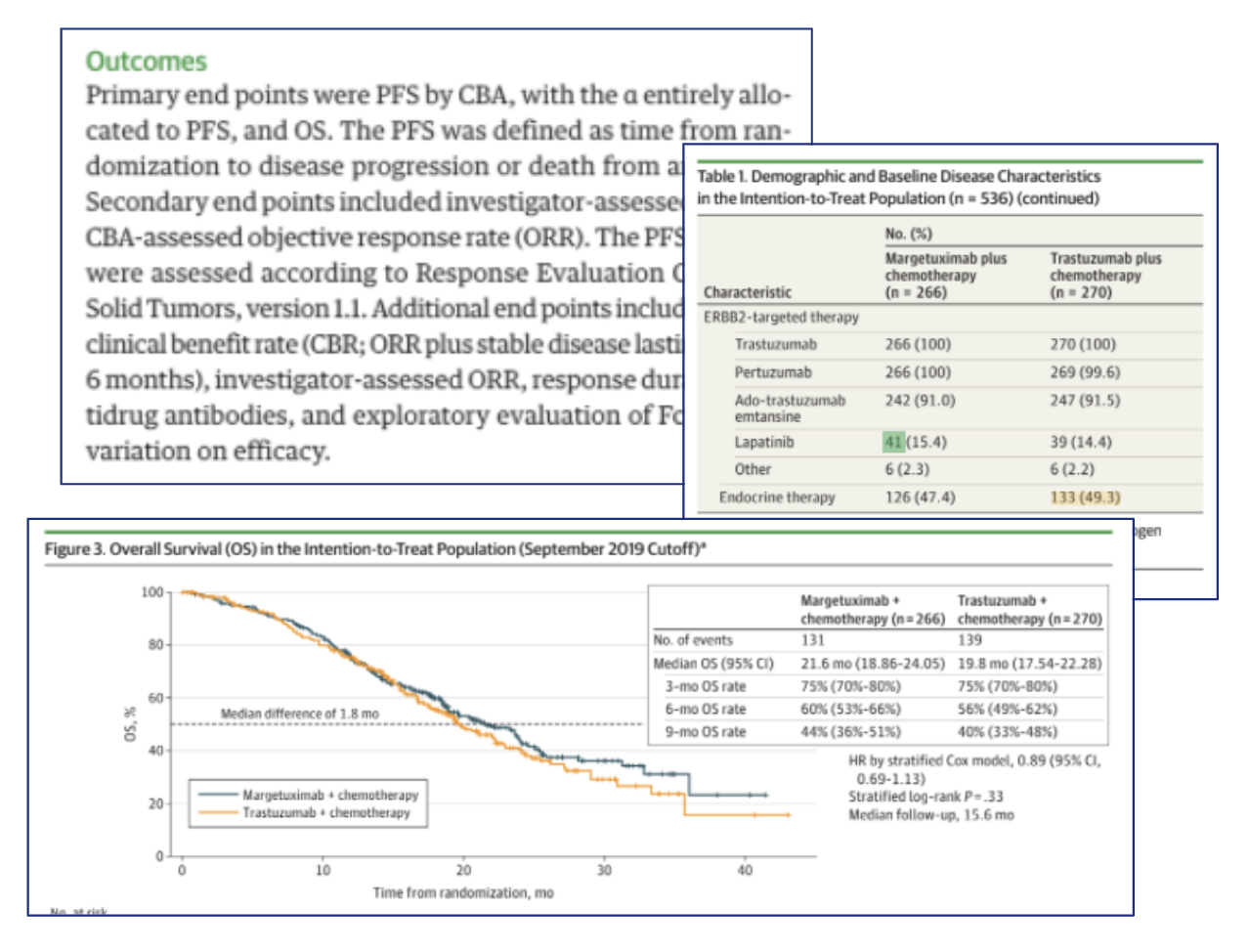
ParseQa has been used for information extraction and analysis from clinical trials data published in journal articles. This system extracts relevant data from unstructured text, tables and images. Also integrated is a question answering and search interface to facilitate intuitive and natural dialogue with the system.
ParseQa has been deployed as an intelligent backend question answering-cum-search engine for FAQbots. ParseQa performs semantic indexing on various document formats, including unstructured text, tables and images in its ambit. Unlike question matching or keyword based chatbots, our smart search API allows natural queries that make the FAQbot intuitive and powerful for end users.