ParseQa: Pushing the Boundaries of Knowledge Search
Sep 21, 2021 · 4 min read
Natural Language Processing(NLP)
AI
Knowledge Management
Search
Question Answering

Most organizations have crucial knowledge scattered across a large number of documents, such as, technical manuals, knowledge articles, patents, policy documents, contracts and scientific publications, often in varied formats. Huge value is created by making this knowledge searchable and extracting the valuable insights therein. To this end, Inscripta’s ParseQa suite of libraries builds on the latest research in Document Processing, NLP and Search to create cutting-edge solutions that can be customized for a variety of domains and use-cases with little effort.
ParseQa can be used to enhance the capabilities of a wide range of enterprise applications such as automated helpdesks, FAQ chatbots, review-insight dashboards, product discovery tools and knowledge search, and can help to leverage the true potential of heterogeneous knowledge repositories of any size. The key features of ParseQa include:
- Finding precise information from deep inside knowledge bases
- Answering ad hoc questions at different levels of granularity
- Generating relevant questions from data for automated FAQ creation
- Easy adaptation/extension for different domains
Technology Pillars: Search, NLP & Document Processing
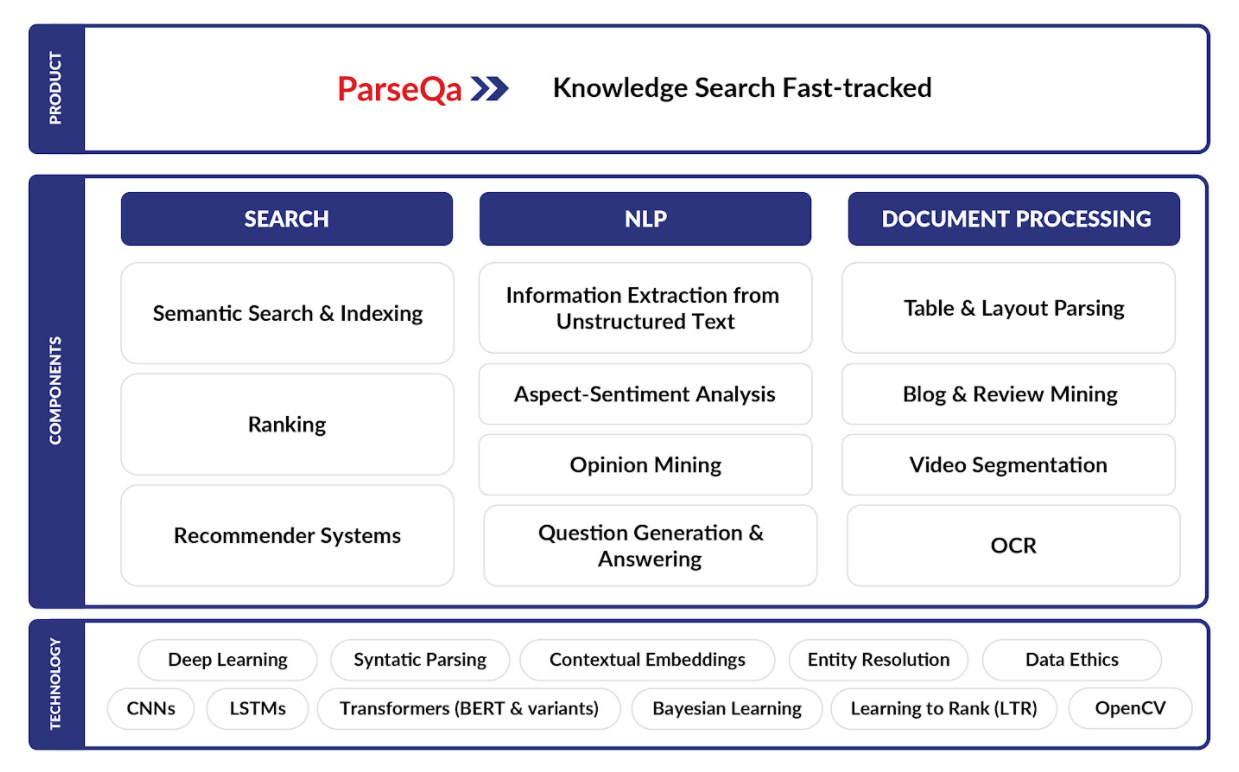
The three technology pillars shown in the figure above, extended with refinements based on multiple deployments, differentiate ParseQa from most Knowledge Search and NLP systems in the market. ParseQa can drastically reduce the time and effort required to get to a real-world solution.
ParseQa’s components have been validated and battle-tested through many challenging client projects, including:
- Information Extraction from journal articles
- QA from technical manuals
- Extraction of relevant chemical compounds from patents
- Insights from product reviews,
Key Challenges Addressed by ParseQa
Multiple document formats and structures:
A typical knowledge base consists of a variety of documents in different formats. ParseQa recognizes formats such as PDFs, DOCX, and HTML, including sections and tables in image form. ParseQa handles diverse document structures (review blogs, journal articles, papers, patents, etc.), and can parse and segment both text and tabular elements for titles, headings, captions, etc., depending on the use case.
Deeper extraction of domain-specific insights:
ParseQa uses deep learning and syntactic analysis techniques to extract keywords, keyphrases, and named entities of different kinds. It performs sentiment-analysis and opinion-mining at document, snippet and aspect levels. State-of-the-art models, including BERT and its variants, are used for classification and semantic indexing of relevant sections of text.
Conversational ease combined with fine-grained retrieval:
A good knowledge search system should enable users to simply ask for some specific detail deep inside a particular document pertaining to a specific project, instead of going through a series of steps such as collecting the project documents, selecting the correct file, and then reading through numerous pages to get the section detail you want. ParseQa makes fine-grained semantic search and retrieval possible by combining embeddings, question answering models, and relevance ranking as part of the search algorithm.
Get in Touch
Check out how ParseQa can supercharge your product — to request an assessment or to see a demo of the solutions, drop us a line at
sales@inscripta.ai
. See
product page
for more details.