Case Study: ParseQa for Life Sciences
Oct, 2021
Information extraction and analytics have become a crucial component of modern clinical research. Professionals in this domain require information spread across hundreds of journal articles that report quantitative and qualitative data in heterogeneous formats--this is a time-consuming and error-prone task when performed manually.
The requirements from ParseQa were to improve the speed and accuracy of the process by sifting through the documents, extracting and collating relevant information, and providing easy-to-consume answers in an on-demand fashion. ParseQa was deployed as a verifiable extraction pipeline to provide data in appropriate formats for a range of downstream analyses, and also a user-friendly conversational interface for professionals to simply ask questions in a natural language, to radically ease their workflow.
The Customizable ParseQa Platform
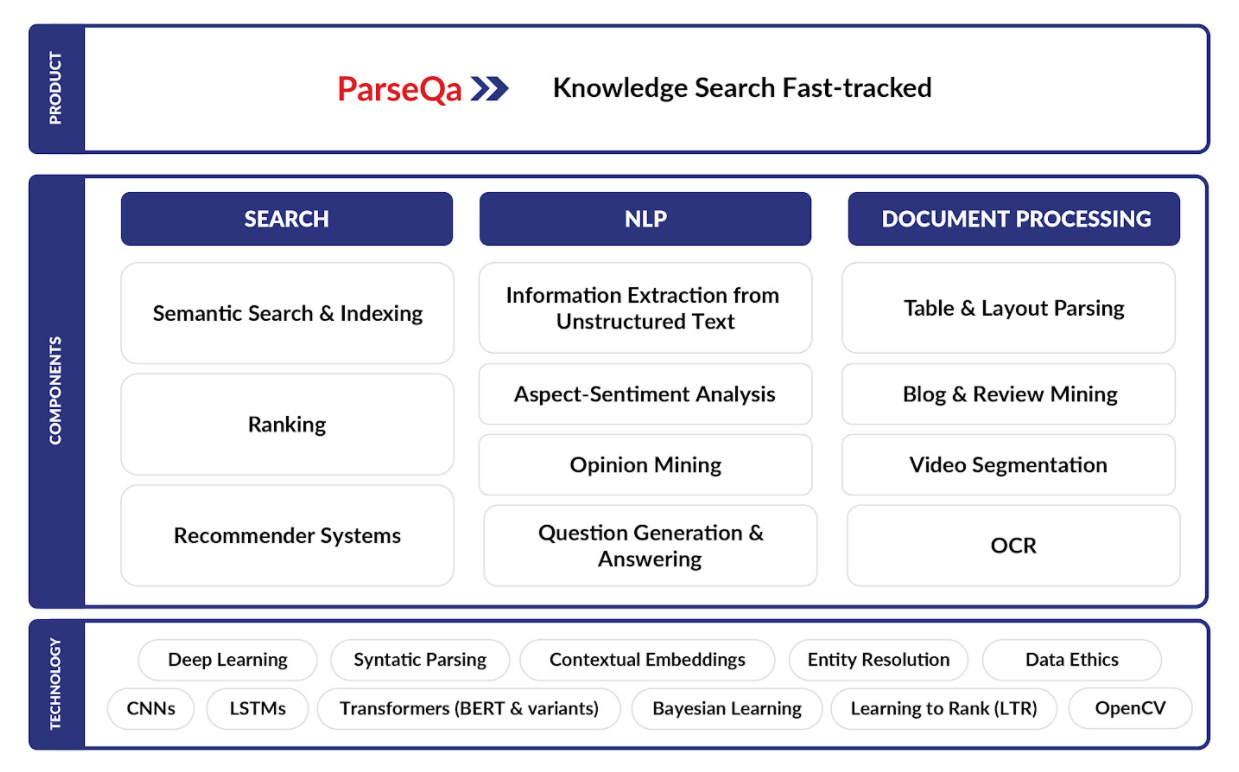
ParseQa technology stack
ParseQa is a state-of-the-art Natural Languague Processing (NLP) system from Inscripta AI that combines information extraction, semantic search and question answering (QA) to leverage large heterogeneous knowledge repositories effectively. ParseQa has been customized for various use-cases, such as a QA-bot for technical manuals, a chemical compound-extraction system for patents, and insight dashboards from product reviews.
ParseQa, as adapted for Clinical Trial Data Analysis, is a system that can be used to extract relevant data from unstructured text, tables and images in scientific papers in various formats such as PDF, DOCX, and HTML, ensuring that all the bases are covered in terms of sources and locations of important information. In order to improve the accuracy further the NLP models were adapted to the scientific/medical domain. ParseQa also provides an integrated question answering-cum-search interface to facilitate intuitive and natural dialogue with the system.
Examples of unstructured text, tables and images in scientific papers
Key Features
Extraction of quantitative data like population characteristics, efficacy outcomes, and adverse effects
Extraction of qualitative data like study details, inclusion/exclusion criteria, and investigator details
Analytics layer for quick insights from extracted data
Natural language querying for easy access to the wealth of extraced data
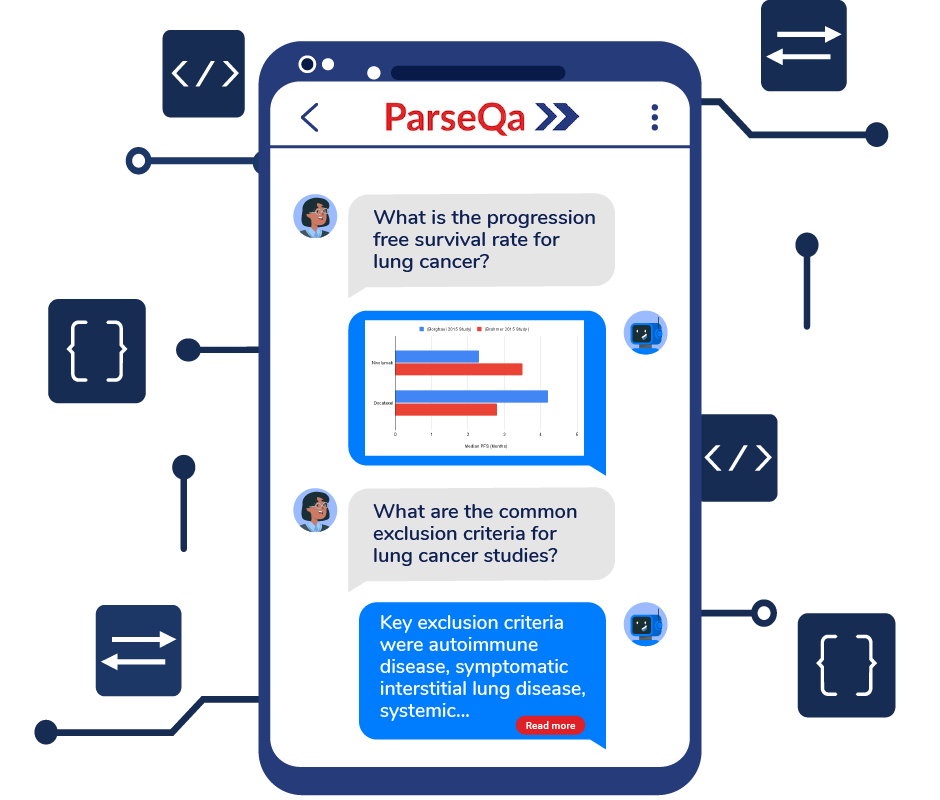
Natural language querying of extracted data
Impact
- Quick automated extraction with comprehensive coverage
- Easy vetting for quality-assured and enriched data pipelines
- Most standard parameters pre-configured
- Easy configuration for new parameters
- Distinctive question answering-cum-search interface
- Analytics layer for quick insights
- Extendable for automated data fetching
Get in Touch
Check out how ParseQa can supercharge your product — to request an assessment or to see a demo of the solutions, drop us a line at
sales@inscripta.ai
. See
ParseQa product page
for more details.