✨ Why Choose ParseQa
What Sets ParseQa Apart
The enterprise-grade solution for secure, accurate, and efficient document intelligence

Secure
On-Prem LLM Option
No external APIs in use. All models (including LLMs) run in offline mode, ensuring complete data privacy and zero cloud dependency
100% Air-gapped deployment
Zero data leakage
Complete control

Flexible
Highly Configurable
Effortlessly adapt the solution to align with your document types, knowledge bases, and specific curation targets
Custom workflows
Domain adaptation
Flexible integration

Optimized
Task-Specific Excellence
AI solutions optimized for specific use cases, delivering superior accuracy and efficiency for your unique business needs
Adaptable to your needs
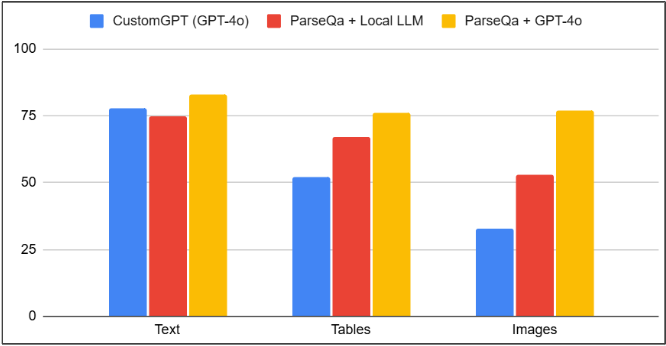
Multimodal support
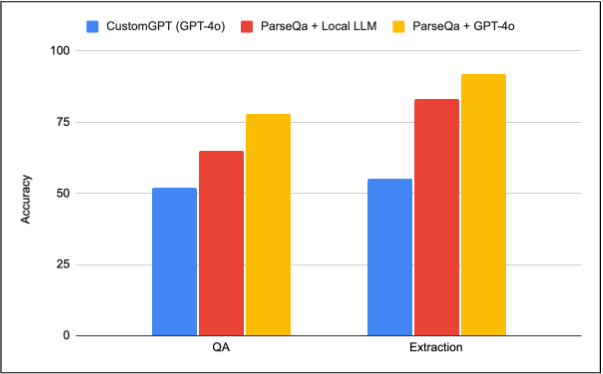
Proven results